Μια περιγραφή του δημοσκοπικού μας μοντέλου.
Παρακάτω ακολουθεί μια σύντομη περιγραφή του δημοσκοπικού μοντέλου του kassiope.org.
Ακολουθώντας το διεθνές παράδειγμα το δημοσκοπικό μοντέλο του kassiope.org είναι μια προσπάθεια για να γίνει μια αξιόπιστη καταγραφή των δημοσκοπικών ποσοστών και κατ’επέκταση της πολιτικής κατάστασης στην Ελλάδα. Εξερευνά δηλαδή μια κριτική που ακούγεται συχνά ως προς την αξιοπιστία των δημοσκοπήσεων και στο κατά πόσο αυτές χειραγωγούνται από επιχειρηματικά και πολιτικά συμφέροντα. Η αξιοπιστία η μη των δημοσκοπήσεων, το αν συστηματικά παρουσιάζουν διαστρεβλωμένα αποτελέσματα καθώς και άλλες παράμετροι μπορούν να ποσοτικοποιηθούν και ερευνηθούν με στατιστικές μεθόδους. Αποτελούν δηλαδή μια κατεξοχήν περίπτωση όπου τα στατιστικά δεδομένα μπορούν να δώσουν μια έστω μερική απάντηση.
Κατευθυντήριες γραμμές.
Η βασική ιδέα πίσω από την ανάλυση μας είναι πως πολλές δημοσκοπήσεις μαζί είναι καλύτερες από μία μεμονωμένη δημοσκόπηση.
- Σκεφτόμαστε πιθανοτικά. Σε κάθε δημοσκόπηση υποθέτουμε πως υπάρχει τυχαίος θόρυβος που είναι αναπόδραστος. Αυτό μπορεί να συμβεί για διάφορους λόγους, όπως είναι για παράδειγμα η εγγενής τυχαιότητα στην επιλογή ενός δημοσκοπικού δείγματος. Κοιτώντας πολλές δημοσκοπήσεις μαζί μπορούμε να υπολογίσουμε την κατανομή τους δηλαδή μια μέση τιμή και μια τυπική απόκλιση.
- Πολλοί δημοσκόποι, και δεξιάς και αριστερής πολιτικής κατεύθυνσης, φαίνεται απ’τα πειράματα μας πως εμφανίζουν σταθερές αποκλίσεις απ’την σωστή καταγραφή των δημοσκοπικών ποσοστών. Οι μετρήσεις τους δηλαδή δίνουν σταθερά μεγαλύτερα ποσοστά σε ένα απ’τα δύο μεγάλα κόμματα, στην Νέα Δημοκρατία ή στον ΣΥΡΙΖΑ. Αυτοί οι δημοσκόποι δηλαδή, θεωρούμε πως είναι μεροληπτικοί υπέρ του ενός ή του άλλου κόμματος, είτε εκούσια είτε ακούσια.
Μπορούμε να εκτιμήσουμε στατιστικά τις παραπάνω ποσότητες, την μεροληψία του κάθε δημοσκόπου και τον ιστορικό θόρυβο στις μετρήσεις του. Έπειτα μπορούμε να χρησιμοποιήσουμε τις παραπάνω πληροφορίες για να δώσουμε μεγαλύτερο ή μικρότερο βάρος σε κάθε μεμονωμένη δημοσκόπηση και συνδυάζοντας πολλές δημοσκοπήσεις να κάνουμε μια πιο αξιόπιστη εκτίμηση των ποσοστών κάθε κόμματος.
Μια λεπτομερής περιγραφή του δημοσκοπικού μοντέλου.
1. Συλλέγουμε ιστορικά δεδομένα και κάνουμε την εκτίμηση μας για την πραγματική εκλογική επιρροή.
Το πρώτο βήμα στην εκτέλεση μιας στατιστικής ανάλυσης είναι η συλλογή δεδομένων. Συλλέγουμε τα αποτελέσματα των δημοσκοπήσεων από τις κύριες δημοσκοπικές εταιρείες για όλα τα μεγάλα ελληνικά κόμματα από το 2012 μέχρι το 2021. Τα δεδομένα αυτά έχουν την μορφή χρονοσειρών όπου η μια μεταβλητή είναι ο χρόνος και η δεύτερη μια τιμή εκλογικής επιρροής που είναι η εκτίμηση του κάθε δημοσκόπου. Ο αριθμός των δημοσκοπήσεων δείχνει αρκετές μεταβολές, την εκλογική περίοδο 2012-2015 διαθέτουμε 292 δημοσκοπήσεις, την περίοδο 2015-2019 διαθέτουμε 186 δημοσκοπήσεις, ενώ για την περίοδο 2019-2023 διαθέτουμε προς το παρόν 84 δημοσκοπήσεις.
Σαν παράδειγμα στην παρακάτω εικόνα εμφανίζουμε τις διάφορες δημοσκοπήσεις για την Νέα Δημοκρατία από τον Ιούλιο του 2019 μέχρι και τον Ιούνιο του 2021. Παρατηρούμε πως οι δημοσκοπήσεις εμφανίζουν σημαντικό θόρυβο. Πέρα από τις μεγάλες χρονικές κλίμακες δεν είναι ξεκάθαρο σε κάθε χρονική στιγμή αν τα ποσοστά ανεβαίνουν ή κατεβαίνουν.
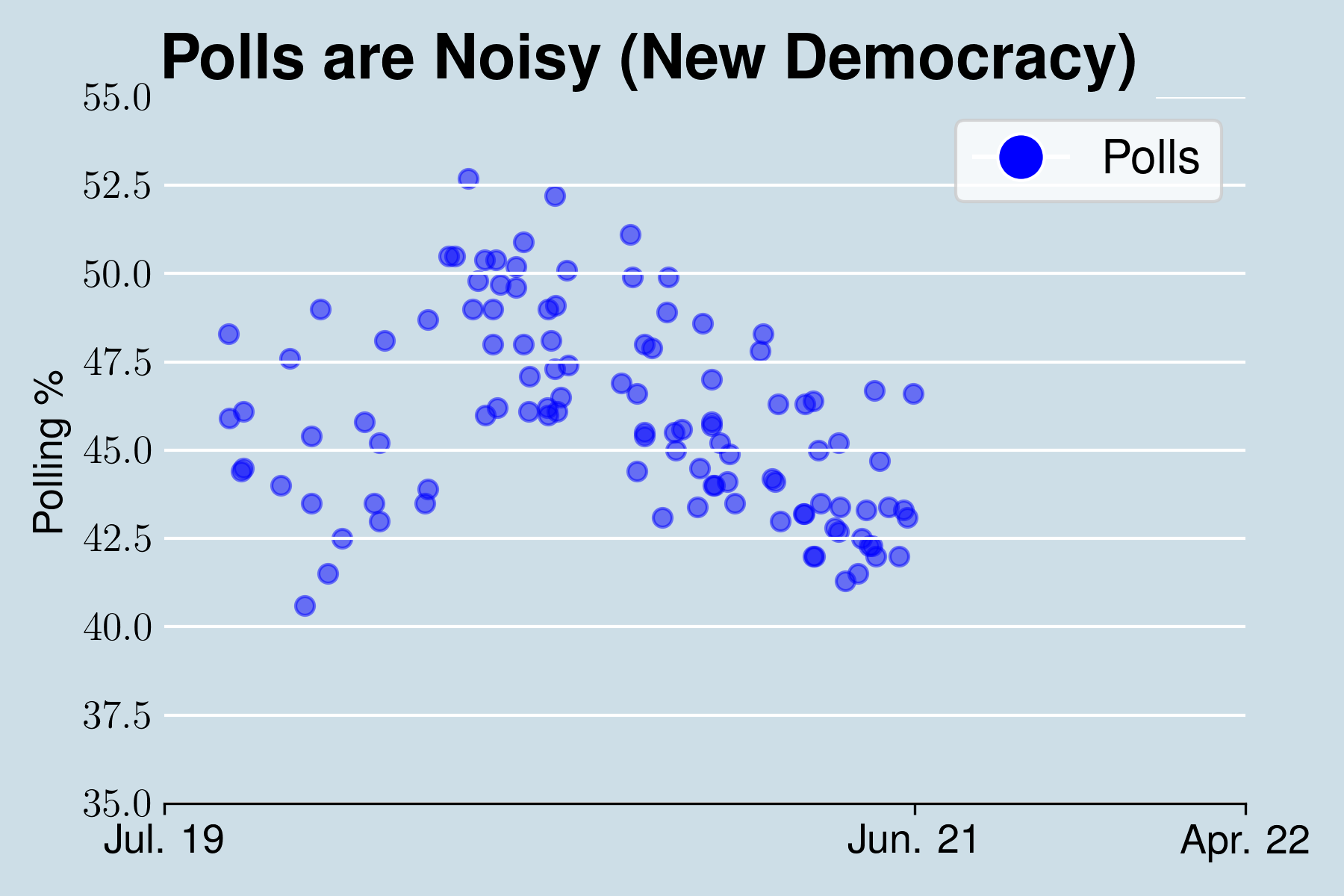
Το επόμενο βήμα είναι να βρούμε μια γραμμή τάσης των δημοσκοπήσεων για κάθε χρονική στιγμή. Αυτή η γραμμή τάσης μοιάζει με έναν μέσο όρο των δημοσκοπήσεων, αλλά διαφέρει με δύο σημαντικούς τρόπους.
-
Υποθέτουμε πως υπάρχει μία μέση τιμή απ΄την οποία προκύπτουν οι διάφορες μετρήσεις μέσω Γκαουσιανού θορύβου. Υποθέτουμε επίσης το επίπεδο του θορύβου παραμένει το ίδιο για κάθε χρονική στιγμή της χρονοσειράς και το εκτιμούμε αυτόματα μέσω μιας τεχνικής μηχανικής εκμάθησης.
-
Υποθέτουμε πως σε κάθε χρονική στιγμή ο μέρος όρος (η γραμμή τάσης) προκύπτει από τις μετρήσεις που έχουν γίνει στο πρόσφατο χρονικό διάστημα.
Στον βαθμό που υπάρχουν δημοσκοπικές εταιρείες και αριστερής και δεξιάς κατεύθυνσης η γραμμή τάσης θα είναι πιο αξιόπιστη από οποιαδήποτε μεμονωμένη δημοσκόπηση. Βλέπουμε παρακάτω το παράδειγμα της γραμμής τάσης για τα δεδομένα της Νέας Δημοκρατίας.
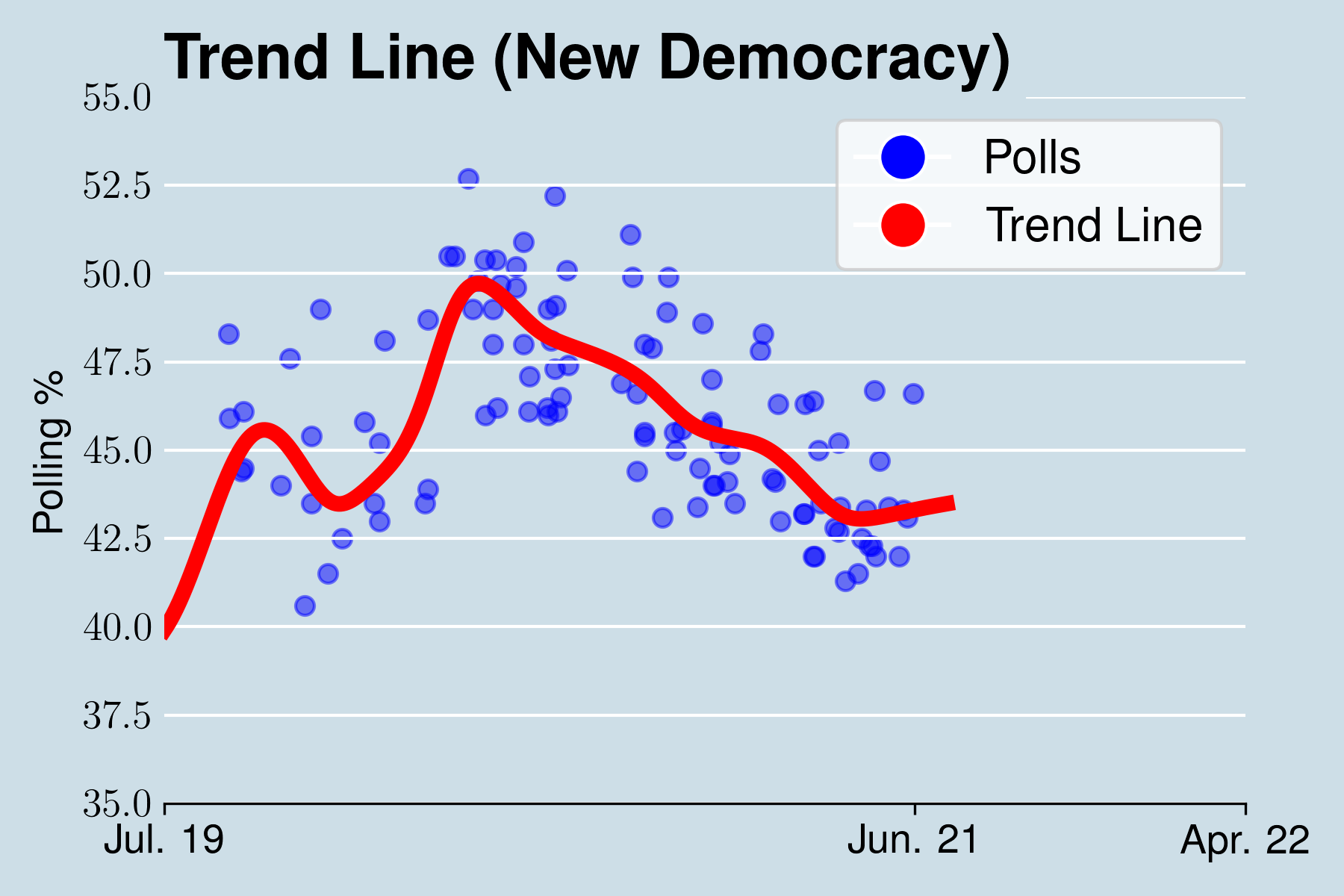
2. Υπολογίζουμε της κομματικής μεροληψίας κάθε δημοσκόπου.
Χρησιμοποιούμε την παραπάνω πρώτη εκτίμηση της πραγματικής εκλογικής επιρροής για να υπολογίσουμε τις παραμέτρους αξιοπιστίας κάθε δημοσκόπου. Η πρώτη παράμετρος αξιοπιστίας που υπολογίζουμε είναι η μεροληψία κάθε δημοσκόπου. Συγκεκριμένα:
-
Αφότου υπολογίσουμε τις γραμμές τάσης υπολογίζουμε την μεροληψία, σαν την μέση απόκλιση κάθε δημοσκόπου από την γραμμή τάσης.
-
Εστιάζουμε στην μεροληψία υπέρ ή κατά τις Νέας Δημοκρατίας και του ΣΥΡΙΖΑ μίας και αυτά τα δύο κόμματα αποτελούν τους δύο κυρίαρχους πόλους του δικομματισμού, και είναι σε αυτά τα κόμματα που εμφανίζεται η πιο έντονη μεροληψία.
-
Για να πάρουμε μία μοναδική τιμή αθροίζουμε τις μεροληψίες ως προς τα επιμέρους κόμματα. Πιο θετικές τιμές δείχνουν μεροληψίας υπέρ της Νέας Δημοκρατίας, ενώ αρνητικές τιμές δείχνουν μεροληψία υπέρ του ΣΥΡΙΖΑ.
Παρακάτω βλέπουμε πως φαίνεται οπτικά η συστηματική απόκλιση ενός δημοσκόπου από την γραμμή τάσης.
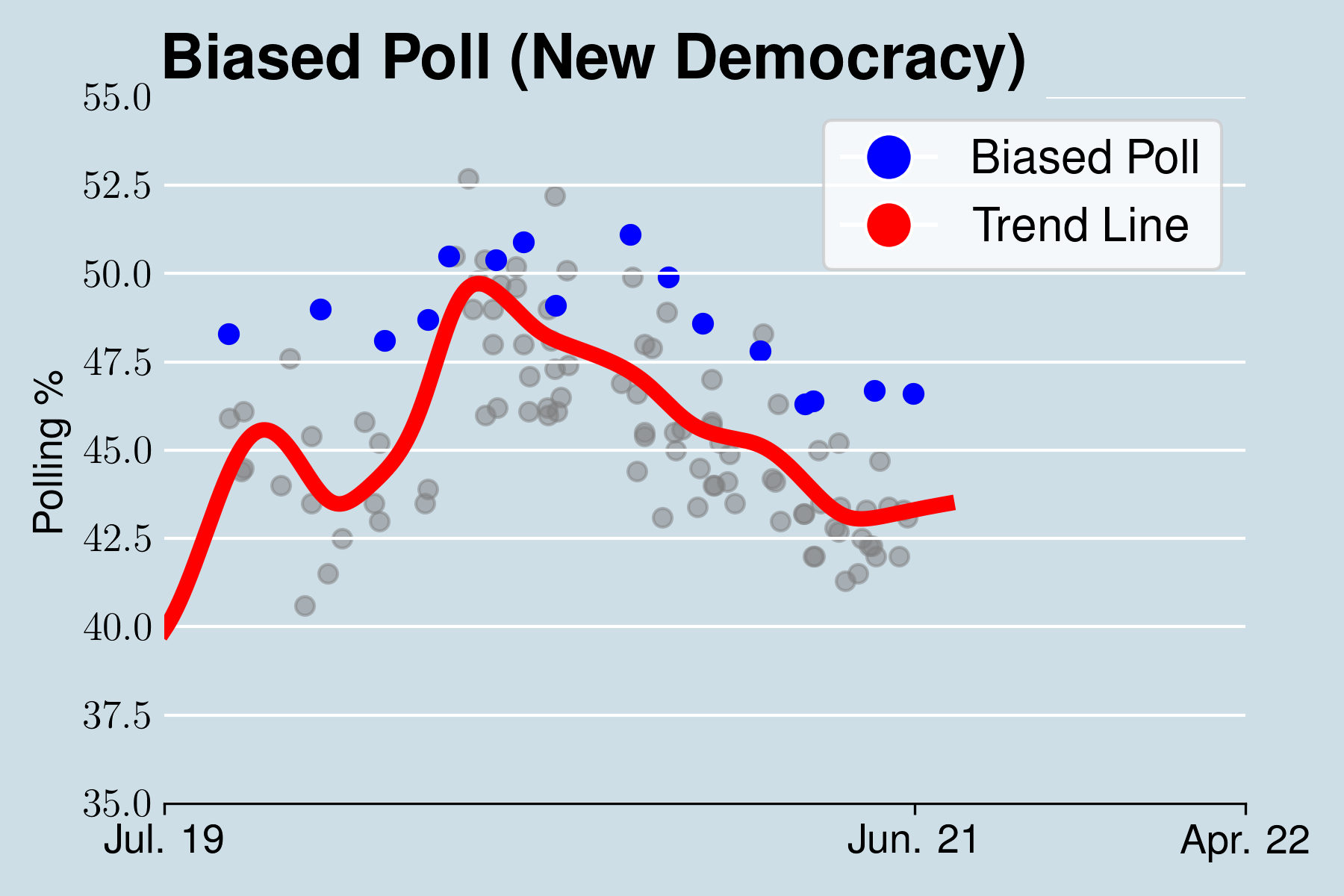
Τα δημοσκοπικά αποτελέσματα αυτού του δημοσκόπου αποκλίνουν συστηματικά από την γραμμή τάσης, συγκεκριμένα υπολογίζει συστηματικά υψηλότερα ποσοστά υπέρ της Νέας Δημοκρατίας.
Παρακάτω βλέπουμε για διάφορες δημοσκοπικές εταιρίες την μέση απόκλιση υπέρ ή κατά των παραπάνω δύο κομμάτων για την χρονική περίοδο 2012-2019, σε σχέση με την γραμμή τάσης που υπολογίσαμε.
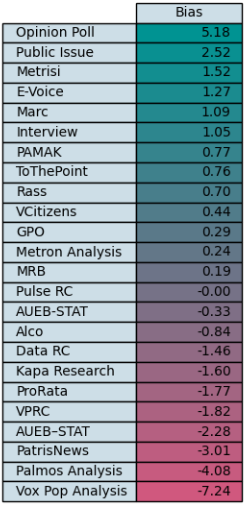
Κάποιες από τις παραπάνω δημοσκοπικές εταιρείες μπορεί να μην είναι γνωστές στο ευρύ κοινό, σε ένα ξεχωριστό άρθρο αναλύουμε τις παραπάνω περιπτώσεις διεξοδικά. Αυτό είναι και ένα πρώτο τεστ προκειμένου να ελέγξουμε αν η γραμμή τάσης μας είναι αξιόπιστη.
- Τα αποτελέσματα δείχνουν κομματική μεροληψία και προς τον ΣΥΡΙΖΑ και προς την Νέα Δημοκρατία, με τρόπο ο οποίος είναι λογικός, δηλαδή δημοσκοπήσεις που γίνονται κατά παραγγελία μέσων φίλα προσκείμενων στο ένα ή στο άλλο κόμμα ευνοούν το κόμμα αυτό.
Είναι σημαντικό επίσης πως αυτό το αποτέλεσμα προέκυψε απευθείας απ’τα δεδομένα χωρίς κάποια δική μας πρότερη υπόθεση.
3. Αφαιρούμε την κομματική μεροληψία του κάθε δημοσκόπου.
Στην συνέχεια μπορούμε να αναπροσαρμόσουμε τα δεδομένα μας προκειμένου να λάβουμε υπόψιν μας την παραπάνω συστηματική απόκλιση κάθε δημοσκόπου. Πλέον οι μετρήσεις κάθε δημοσκόπου δεν θα εμφανίζουν μια συστηματική απόκλιση σε σχέση με την γραμμή τάσης, αλλά ένα τυχαίο σφάλμα. Παρακάτω βλέπουμε τον ίδιο δημοσκόπο με πριν αλλά αφότου έχουμε αφαιρέσει απο αυτόν και τους υπόλοιπους την τιμή μεροληψίας τους.
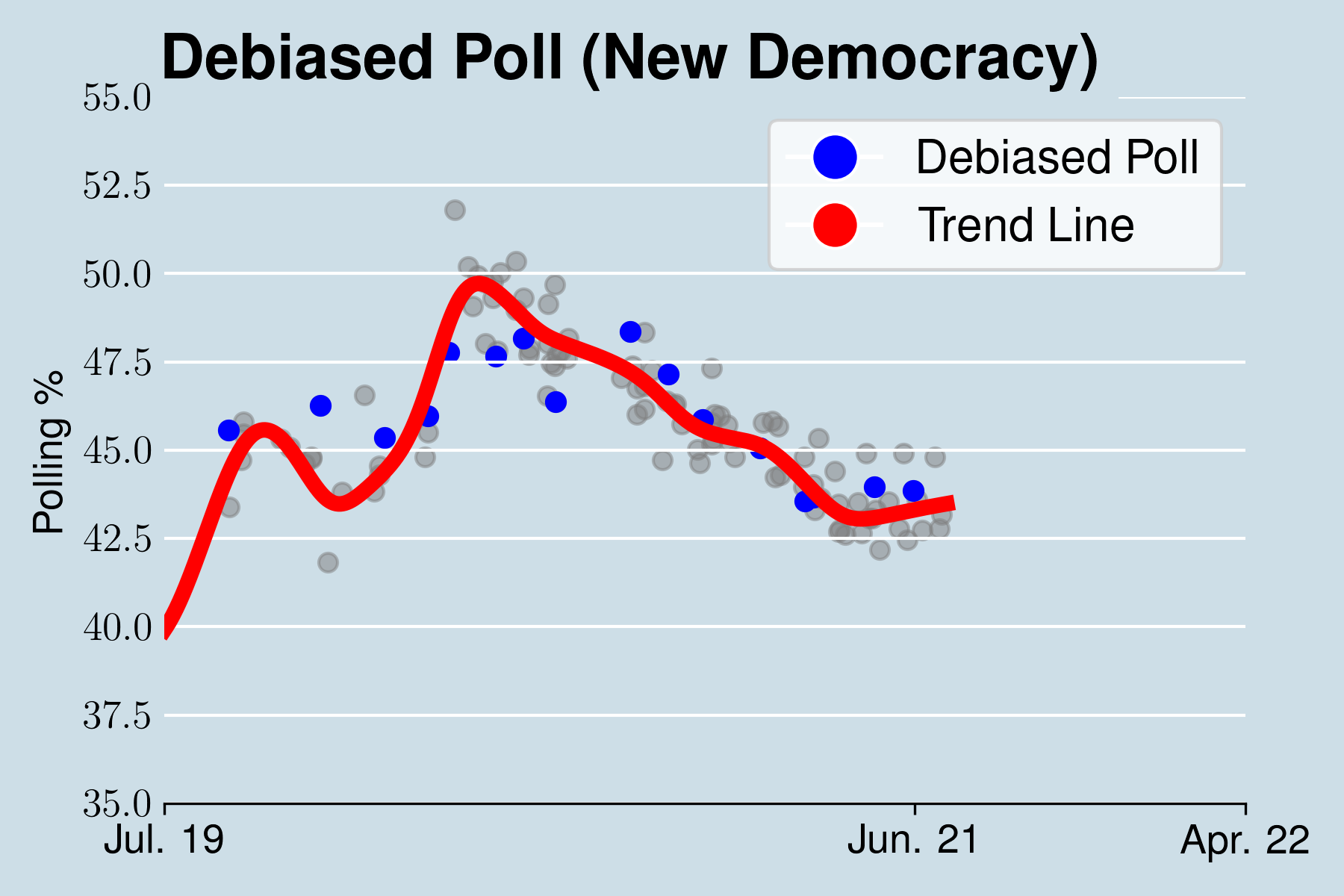
Παρατηρούμε πως οι διάφορες δημοσκοπήσεις εμφανίζουν πολύ μικρότερη διακύμανση από πριν επιπλέον για τον συγκεκριμένο δημοσκόπο η απόκλιση του από την γραμμή τάσης είναι πλέον πότε αρνητική και πότε θετική, πιο κοντά δηλαδή σε αυτό που θα θεωρούσαμε τυχαίο σφάλμα.
4. Υπολογίζουμε μια καινούργια γραμμή τάσης.
Πλέον μπορούμε να υπολογίσουμε μια καινούργια γραμμή τάσης για κάθε κόμμα. Οι μετρήσεις μας θα είναι πλέον πιο κοντά στις πραγματικές τιμές. Για την χαραξη των γραμμών τάσης χρησιμοποιούμε ένα στατιστικό μοντέλο που ονομάζεται Gaussian Process. Το βασικό πρόβλημα των δημοσκοπήσεων είναι πως δεν μπορούμε να ξέρουμε με σιγουριά ποια είναι η σωστή τιμή κάθε στιγμή. Το παραπάνω στατιστικό μοντέλο εμπεριέχει κάποιες διαφειλάξεις για τις προβλέψεις του. Διαισθητικά δεν μπορεί να είναι “πολύ λάθος”, ενώ ταυτόχρονα μπορούμε να το συγκρίνουμε με άλλα παρόμοια μοντέλα και να επιλέξουμε το καλύτερο χωρίς να ξέρουμε ποια θα έπρεπε να είναι η σωστή τιμή των δημοσκοπήσεων.